本文由 Gideon(AI)翻译自英文原版。
自从 ChatGPT 吸引了所有人的目光,AI 便一直处于聚光灯下。它改变了我们使用互联网的方式,也改变了很多人的写作习惯和日常工作方式。技术已经到位,那么接下来呢?从这里出发,未来将走向何方?
在你开始阅读的时候,也许会疑惑:为什么我们又在聊这个话题?自 2023 年以来,人们已经谈论了太多关于 AI 及其能力的内容,到了 2025 年,你可能真的不想再听了。请先耐心听我说,这里还有更多值得探讨的内容。
整体概述 链接到标题
要理解下一步会发生什么,我们需要回顾一下我们是怎么走到今天的。今天,我们主要聚焦于大型语言模型(LLM),因为这是目前讨论最多的话题。
什么是 LLM?我原本打算专门写一节详细介绍 LLM,但相关领域已经有很多比我更有经验的专家写过很好的文章了。作为入门,我推荐阅读 Luis 的这篇文章: 点击这里。这篇文章对 LLM 模型和 RAG 应用做了很好的解释。
简单来说,大型语言模型是一种能够处理数十亿乃至数万亿条数据、并理解所给信息的系统。那么,要实现这一点,我们需要什么?
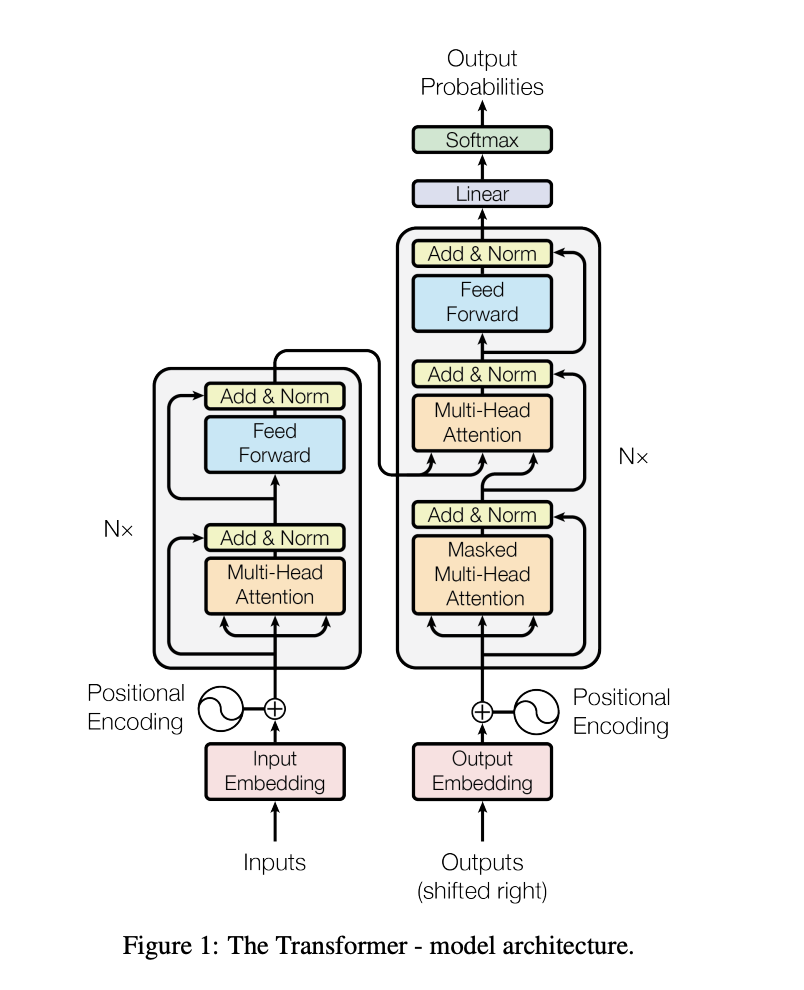
要理解其背后的架构,有一篇论文解释了什么是"Transformer",即 “Attention is All You Need”。这篇论文详细阐述了 Transformer 的概念,以及它为何优于 RNN。它是序列建模与转换的核心,注意力机制的概念使得模型能够对任意距离的序列依赖关系进行建模。这一设计实现了更高程度的并行化,并在大幅减少训练时间的情况下(例如在 8 块 P100 GPU 上仅需 12 小时)达到了最先进的翻译质量。Transformer 代表了序列建模领域的重大变革,突破了顺序计算的限制。不过,训练像 GPT-4 这样的现代大型语言模型需要更长的时间和更强的计算能力。
语言是如何被处理的 链接到标题
要理解 LLM 如何处理语言,需要从以下几个角度来看,这也是你在大学里可能会学到的内容:
- 分词(Tokenize)
- 上下文理解(Context understanding)
分词(Tokenization) 链接到标题
回想一下你最初学英语的方式。你从 Apple、Table、Pear、Peanuts、Window 这样的单词开始,甚至在那之前,你先从 A、B、C、D、E……这样的字母开始。分词也是同样的道理。分词有几种不同的方式,比如对于句子"An apple is on a table"(一个苹果在桌子上),分词后可能会得到 [“An”,“apple”,“is”,“on”,“a”,“table”],这叫做词级分词(word-level tokenization);此外还有子词分词(Subword Tokenization)和字符级分词(Character-Level Tokenization),后者会将单词拆分到字符层面。
上下文理解(Context Understanding) 链接到标题
上下文理解是指 NLP 模型根据周围语境来理解单词或短语含义的能力。这一点至关重要,因为单词的含义会随着使用方式的不同而改变。比如"You are sick"这句话,在不同情境下可以有完全不同的意思:如果你在和某人说话,“You are sick"可能是在说对方真的生病了;而在你刚刚看到某人在攀岩墙上完成了一个超厉害的动作之后大喊"You are sick”,那这句话的意思就是你在夸赞对方,表达惊叹。语言中隐含着很多潜在语境,这对机器来说是很难理解的。在我举的这些例子中,机器当然无法仅凭这几个简单的词就理解发生了什么,因为我们缺少太多上下文信息。要让机器明白你在说什么,就需要补充更多内容。如果我们把第一句改成"You are sick, you probably should see a doctor"(你生病了,你可能应该去看医生),那么通过上下文理解,模型就会知道你指的是对方真的生病了。同样,第二种情境可以改成"That was a sick move, how did you go from the first hold to the second hold on the bouldering wall"(那个动作太秀了,你是怎么从第一个点到第二个点的)。这说明了在与 LLM 交互时,提供完整、清晰的输入是多么重要。
训练 链接到标题
有了 Transformer 架构和语言处理能力,我们的模型框架就搭建好了。下一步是对模型进行训练。
训练分为两个部分:预训练(pre-training)和微调(fine-tuning)。我们现在使用的大多数 LLM 都已经经过了预训练。这些模型被喂入大量、多样化的数据集,根据统计输出学习预测序列中的下一个词。这也是我认为微调非常重要的原因。比如,如果你想从几份特定文档中获取专业信息,就需要把这些文档输入到预训练模型中,让它专门学习这一领域的知识。这就是所谓的领域特定微调(Domain-Specific Fine-Tuning)。微调还有其他多种方式,推荐阅读 这篇 DataCamp 文章,文章解释了不同类型的微调方式并提供了示例,帮助你更好地理解。
AI 在 ERP 中的应用挑战 链接到标题
我有 ERP 背景,有 SAP 和 Salesforce 的实际经验,熟悉一般制造业的业务流程,主要包括销售、采购和生产。现在有了 AI 工具,我们如何在 ERP 中应用它?
我认为 AI 在 ERP 领域的潜力是巨大的。从长远来看,它可以帮助降低成本,并提高业务流程效率。然而,我们也需要关注几个潜在问题:
-
技术债务 只要在科技行业工作过,技术债务这个概念对你来说应该不陌生。有句老话说得好:如果没坏,就别动!这不仅适用于软件,也适用于所使用的硬件。我们可能需要审视企业当前的基础设施,某些情况下,硬件可能需要升级,配备更强的 CPU 和 GPU,以获得更强的计算能力来应对必要的计算量。这主要是针对依赖本地(on-premises)硬件运行的系统。(SAP BASIS 永不过时!)
对于已经在云端运行的系统,你也需要确认所选用的云平台能够支撑 AI 应用所需的计算量。
上面提到的技术债务主要是硬件层面,此外还需要审视某些建于 1950 或 60 年代的代码——也许是时候更新了,或者用更好的工具替代某些功能。比如,将 COBOL 翻译成 Java 可能正当其时。
-
数据不完整 / 数据质量差 我在数据迁移项目和组织合并项目中的经历告诉我,数据永远是乱的。LLM 的核心是你输入到预训练模型中用来精炼它的大量文本和信息。当你的数据质量很差时,也很难帮助模型区分"好数据"和"坏数据",从而无法提供可靠的输出。一个关键步骤是深入数据库,理解数据的含义,同时识别哪些数据有利于为特定目的精炼预训练模型。这也是为什么使用有针对性的精准数据进行微调如此重要。通用预训练模型可能并不适合你的具体需求。但是,小型、有针对性的数据集也带来了一些挑战,我们将在下一点中讨论。
-
数据偏见与潜在错误信息 这可能是上一点的延伸,但我想单独拿出来讨论。 作为人类,当你阅读一篇文章时,你可以借助自己的经验、现有知识和直觉来判断,并对接收到的信息形成自己的观点;有时即使是人类,也需要依赖额外的信息和研究才能理解所接收的内容。机器只能执行被告知的操作,算法由人类开发,数据由人类提供,不同的人在开发软件、收集和应用数据时会有不同的立场。我很喜欢 “Artificial Intelligence”(Mueller、Massaron、Diamond 著)中的一个例子:一辆车撞了行人,当警察分别询问司机、行人和旁观者时,他们各自的陈述都不同,尽管从各自的立场来看,他们都在说真话。
在书中,Mueller、Massaron 和 Diamond 还讨论了数据中的五种不实情况,包括:错误陈述(Commission)、遗漏(Omission)、视角偏差(Perspective)、偏见(Bias)和参照框架(Frame of reference)。在数据收集过程中,局限性往往已经存在——数据来源、收集方式等,都可能导致数据失真。
书中还提到了另一种我此前忽视的情况:也存在故意制造的偏见数据。这类数据会大幅增加错误信息出现的可能性,因为这些数据/信息是被设计用来引导公众按照某些人的利益去思考的。
说到数据,我还想提一点:对于 ChatGPT 这类工具,它们用于训练模型的数据是历史数据,其中的信息可能已经过时。这也是为什么在使用这些工具时,我们需要用自己的数据对模型进行精炼,而不应该完全用它们取代 Google 搜索——否则你获取的信息可能是陈旧的。
-
缺乏明确的目标 随着 AI Agent 的兴起,所有东西都想和 AI 搭上边。我们或许应该退一步思考:“我们真的需要 AI 吗?““AI 对我们有什么具体好处?“在某些情况下,一段简单的自动化脚本反而能更好地解决问题。在系统中引入 AI 并不是一劳永逸的事,AI 相关流程上线后仍然需要持续维护。在这里,ROI(投资回报率)分析至关重要。
我个人认为,更好的方式是:先忘掉 AI 的存在,第一步是理解需求和我们要解决的问题。把 AI 视为可以利用的众多技术工具之一,帮助更好地解决问题。因此,AI 工具应该是解决方案的一部分,而不是目的本身。
未来展望 链接到标题
综上所述,下一步会怎样?我们是否注定要面临 AI 的崛起?AI Agent 会取代人类吗?我不这么认为。正如我们上面讨论的 AI 面临的挑战,我把这些挑战视为新的机遇。我们需要减少技术债务,用 AI 解决问题,让人类能够专注于更高价值的工作。例如,我看到有些医生在患者就诊时录制谈话内容,并在征得患者同意的情况下使用 AI 进行总结。这样一来,医生可以在与患者交谈时更专注,也减少了就诊后撰写记录的工作量。当然,有人会说这可能侵犯患者隐私,这也是为什么加州出台了三项针对医疗保健相关 AI 和数据隐私的法律:AB-3030、SB-1223、SB-1120。“AB 3030 要求医疗保健提供者披露其是否使用生成式 AI 创建与患者的通讯内容。SB 1223 修订了 2018 年《加州消费者隐私法》,将神经数据纳入敏感个人信息,并允许用户限制企业对其收集和使用。SB 1120 则限制了健康保险公司使用 AI 来确定会员医疗服务必要性的程度。"(《医疗保健、AI 与法律:加州新兴监管格局》)更多详情请参见 Health Care, AI, and the Law: An Emerging Regulatory Landscape in California。
随着越来越多的 AI 工具被开发出来,透明度是关键。向公众清晰说明谈话录音的使用方式以及 AI 在其中所发挥的作用,确保人们对 AI 工具的使用感到放心,这不仅有助于建立公众信任,也有助于展示 AI 的价值与益处。
作为人类,在开发软件和使用任何 AI 相关技术时,我们需要承担更多的责任。人类仍将坐在驾驶座上,而技术则是帮助我们整体推进社会进步的工具。
参考资料 链接到标题
LLM Models and RAG Applications Step-by-Step,作者:Luis Angel Pérez Ramos https://community.intersystems.com/post/llm-models-and-rag-applications-step-step-part-i-introduction
“Attention is All You Need” 论文 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin (2017). Attention is All You Need. https://arxiv.org/pdf/1706.03762
DataCamp LLM 微调文章,作者:Josep Ferrer https://www.datacamp.com/tutorial/fine-tuning-large-language-models
“Artificial Intelligence”,作者:Mueller、Massaron 和 Diamond Mueller, J. P., Massaron, L., & Diamond, J. (2020). Artificial Intelligence for Dummies. Wiley, 第 3 版
Health Care, AI, and the Law: An Emerging Regulatory Landscape in California,作者:Rebekah Ninan https://petrieflom.law.harvard.edu/2024/10/17/health-care-ai-and-the-law-an-emerging-regulatory-landscape-in-california/#:~:text=AB%203030%20requires%20that%20health,can%20be%20directed%20to%20limit.